

🤔 现在,想象我们在开发一款音乐笔记软件,通过强大的 Spotify API 获取当前正在播放的音乐,并显示在 UI 上。现在我们已经能够获取正在播放的音乐,准备建立一个数据库,存储笔记,而笔记和正在播放的音乐绑定。
Spotify API 提供的信息与文档型数据库
Spotify Current-playing API
current-playing API 中,Spotify 会为我们提供一些结构化信息,具体可以查阅 Spotify API 文档。
你能想象到的需要的与笔记相关的信息有:“
- (当前正在播放的歌曲的)歌曲名称
- 专辑名
- 歌手名
- 专辑封面
”这些,这很棒!但为了歌曲的唯一性,我们还需要获取歌曲的身份证(ID)。
现在,想象我们已经把 current-playing API 端点中获取的信息通过 React Context 提供给每一个组件。如果你不知道是什么意思的话也没有关系,总之,只需要用 data 四个字就可以代表 API 中的信息,用下面的语法就可以代表获取相应的信息。
其实我们还需要显示类似于专辑 ID、歌手 ID 等信息便于后期查询,但先用这些好啦。
- 歌曲 ID:currentTrack.item.id
- 歌曲名称:currentTrack.item.name
- 歌手名:currentTrack.item.artists.map(artist => artist.name).join(‘, ‘)
文档型数据库
接下来我们学习数据库的概念。不同于传统的关系型数据库(比如 MySQL),文档型数据库更像是一个巨大的 JSON 文件集合。如果你不知道传统数据库是什么样也没关系,只需要学习文档型数据即可。
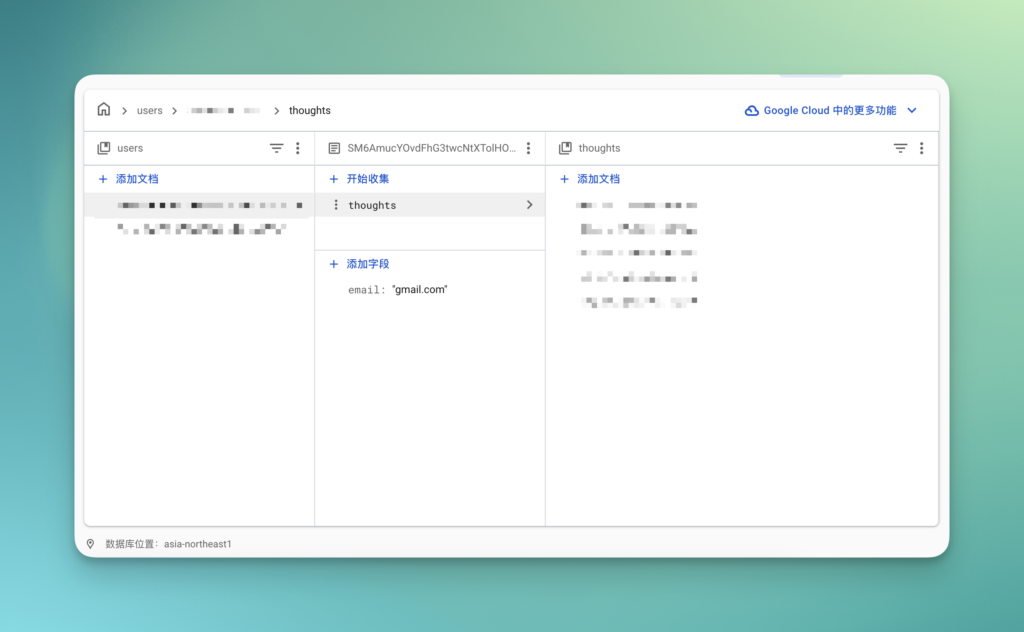
如果你打开访达,就知道什么是文档型数据库了。我们作为 App 开发者,需要分门别类存储用户的信息,所以第一层一定是不同用户的文件夹,每个用户有相互隔离的信息,而文件夹在 Firestore 中称为「集合」。(当然啦,想象我们在用 Notion 的协作功能,可能就不是这样的结构)
在打开文件夹之后,我们想获取的一定是某个文件。在 Firestore 中也是如此,称为「文档」,文档的内部是 JSON 语句。不过特殊的是,即使已经是文档了,也可以在文档的下面继续包含一个子集合,但文件的下面是不能包含文件的;你也不可以在集合的下面再包含一个子集合。
现在我们就创建一个简单的数据库结构吧!
- root.users(集合)
- USERID1(文件)
- email: 123@gmail.com
- name: 51
- NOTES(集合)
- NOTESID1
- content: 好喜欢
- trackID: spt031245
- trackName: supernatural
- artist:Ariana Grande
- createdAt: serverTimestamp
- NOTESID2
- ……
- USERID2
在 Firestore 中,如何分辨集合和文件呢?很简单!如果上方是 📂 文件夹图标则是集合,如果是 📝 文档图标则是文档。你可以清楚地看到,文档的下方可以是集合也可以是字段,而集合下方只能是文档。
在正式开始写代码之前,我们需要进行导入,import { auth, db } from “./firebase”。
想象我已经帮你把 Firebase 授权之类的做好,目前的用户为 user,目前 Spotify API 中 current-playing 返回的信息已经存储在 currentTrack 中,你的数据库为 db。
获取集合和文档的引用:collection(), doc()
使用 addDoc() 就可以往 Firestore 数据库中添加内容,你可以在 Firestore 的官方文档查阅这个函数。
但是在正式使用 addDoc()之前,我们需要先通过const notesRef = collection(db, 'users/${user.uid}/notes');创建引用。创建引用的目的是让代码更加简洁,作为练习你也可以每次直接写上面的内容。collection(db, ‘users/${user.uid}/notes’)的意思是,获取位于 users/user_id/notes 这个位置的集合。这样一来,显然 notesRef 就代表了 notes 这个集合。
获取文档也一样,doc(db, ‘users/${user.uid}/notes/‘notes_id)即可。
你也可以使用多个路径参数的方法书写:
const orderDocRef = doc(db, 'users', 'user123', 'orders', 'order456’);。
对集合操作:addDoc()
因为每一个笔记都是单独的,所以每一个笔记都是一个文档,故使用 addDoc()函数。第一个参数为引用,引用的内容显然是一个集合的地址。第二参数为内容。
try{
await addDoc(notesRef, {
content: thoughts,
createdAt: serverTimestamp(),
trackId: currentTrack.item.id,
trackName: currentTrack.item.name,
artist: currentTrack.item.artists.map(artist => artist.name).join(', '), albumCover: currentTrack.item.album.images[0]?.url
});
} catch (e) {
console.error('添加文档时出错:', e);
}
对文档操作: setDoc(), updateDoc(), deleteDoc(), getDoc()
与之前一样,我们先获取文档的引用。
以下是 Firestore 中常用的几个文档操作函数的详细介绍:
setDoc()
语法:setDoc(docRef, data, options)
例如:await setDoc(userRef, { age: 26 }, { merge: true });
updateDoc()
updateDoc(docRef, data)
例如:await updateDoc(userRef, { age: 27 });
注意:如果文档不存在,updateDoc() 将抛出错误。
此外,updateDoc() 与 setDoc() 的合并模式有如下区别:
| 函数 | 操作方式 | 文档不存在时的行为 |
|---|---|---|
updateDoc()
| 仅更新指定字段,不影响其他字段 | 抛出错误,不创建新文档 |
setDoc()
| 覆盖整个文档 | 创建新文档,覆盖内容 |
setDoc() + { merge: true }
| 仅更新指定字段,不影响其他字段 | 创建新文档,仅设置指定字段 |
deleteDoc()
语法:deleteDoc(docRef)
getDoc()
语法:getDoc(docRef)
这些函数提供了对 Firestore 中文档的基本 CRUD(增删查改)操作。
数据库的查询与显示
我们需要在播放器播放到某首歌的时候播放相应的笔记,当我们打开 Spotoolfy,就可以看到之前的心情陈列在 UI 界面上。显然,我们需要用 user_id 和目前正在播放的歌曲的 trackId 来查询。
用中文来说,应该就是“Hey数据库,请你帮我搜索在 db/User/目前的 user_id 这个文件下的 thoughts 集合里所有字段trackId= currentTrack.item.id 的笔记”。
查询文档需要使用 getDocs()。
getDocs()中应该是一次查询,我们把这次查询定义为:
const q = query(
notesRef,
where('trackId', '==', currentTrack.item.id),
orderBy('createdAt', 'desc')
);
之后使用try{const querySnapshot = await getDocs(q);}就可以了。通过下面的代码,我们再将 querySnapshot.docs 中的每个文档转换成新的对象结构。
const thoughtsList = querySnapshot.docs.map(doc => ({
id: doc.id,
...doc.data(),
// 将 Timestamp 转换为可读时间
createdAt: doc.data().createdAt?.toDate().toLocaleString()
}));
转换后,新的 List 有 id 和原 data 中的字段。由于在 JavaScript 对象中,如果使用相同的键多次,后面的键会覆盖前面的键的值。所以最后一行createdAt: doc.data().createdAt?.toDate().toLocaleString()会覆盖掉 data 中无法解析的 createdAt 内容。
接下来先用 setThoughts(thoughtsList) 设置 thought,再通过一个最简单的 list 组件就可以显示出来:
<List>
{thoughts.map((thought) => (
<ListItem key={thought.id}>
<ListItemText
primary={thought.content}
secondary={`${thought.rating} - ${thought.createdAt}`}
/>
</ListItem>
))}
</List>
练习:同名歌曲
相信你一定会遇到过头疼的事情:Spotify 的年终总结不会把两张专辑中的同一首歌算作一首,而是分开计算。比如说 eternal sunshine 专辑中的「eternal sunshine」和 eternal sunshine(slightly deluxe) 专辑中的「eternal sunshine」。他们都是一样的歌曲,但他们有不同的歌曲 ID(唯一标识符)。
这对于音乐笔记是致命的,所以我们需要在 ThoughtsList 组件的下部增加“可能来自同样歌的想法”。
# 可能来自同一首歌曲的想法:
1. ……
2. ……
请你思考这个组件应该如何修改呢?
如果你没有学习过前端代码,写出查询语句即可。
回复
-
[…] Spotoolfy 开发(1) 从 Spotify 入门 Firestore 数据库 […]
RELATED POSTS
View all

发表回复